Yeni Kayıt
Yeni Kayıt








 Konudaki Resimler
Konudaki Resimler

 önceki
önceki
< Bu mesaj bu kişi tarafından değiştirildi atyay -- 10 Kasım 2011; 22:14:33 > |
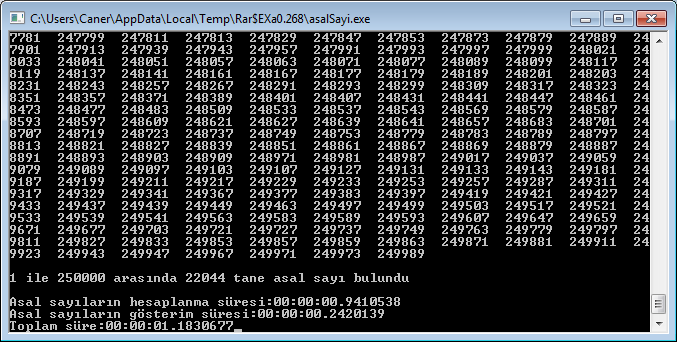






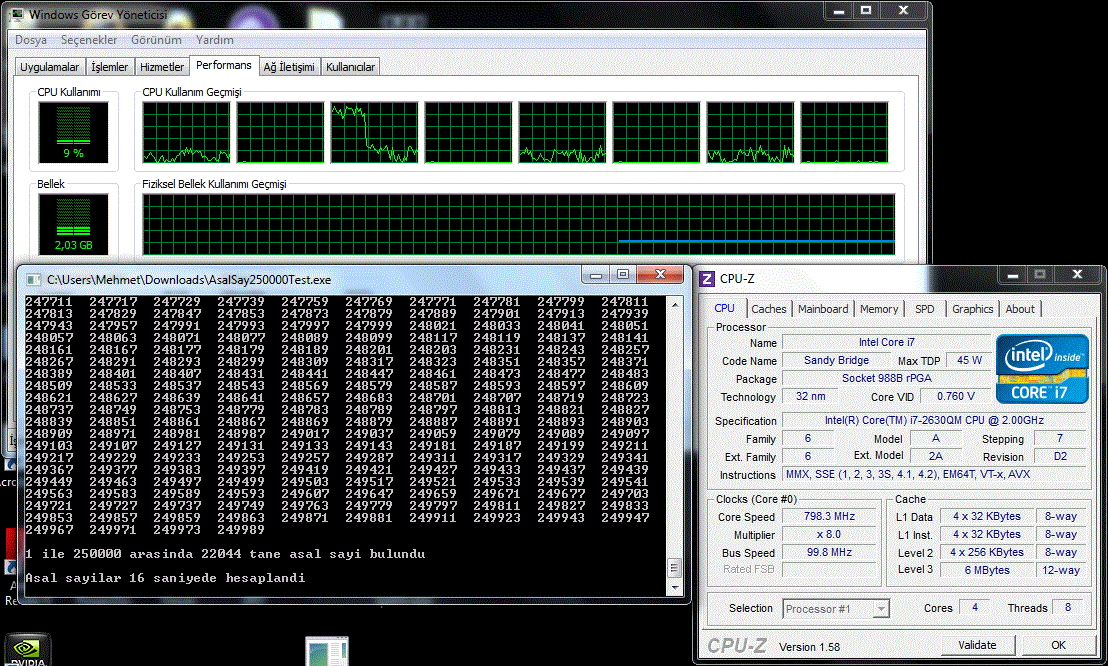

 Belki daha da ilerletilebilir veya Sieve of Eratosthenes'den daha iyi algoritmalar da vardır ama araştırmak ve zaman ayırıp uğraşmak lazım. yine de basitten başlayıp modifikasyonlarla ilerlemek de iyidir. işlemci karşılaştırması için ise multithreaded yapmak lazım. onun için de iki farklı yöntem var. bir tanesi tek bir asal sayı için sieve yapılacak sayıları threadler arasında paylaştırmak. diğeri de her thread için farklı asal sayı belirleyip threadlerin o sayıya göre sieve yapması. bu sıralar belki uğraşamayabilirim ama burada bunları benden iyi yapabilecek çok yetenekli arkadaşlar gördüm.
Belki daha da ilerletilebilir veya Sieve of Eratosthenes'den daha iyi algoritmalar da vardır ama araştırmak ve zaman ayırıp uğraşmak lazım. yine de basitten başlayıp modifikasyonlarla ilerlemek de iyidir. işlemci karşılaştırması için ise multithreaded yapmak lazım. onun için de iki farklı yöntem var. bir tanesi tek bir asal sayı için sieve yapılacak sayıları threadler arasında paylaştırmak. diğeri de her thread için farklı asal sayı belirleyip threadlerin o sayıya göre sieve yapması. bu sıralar belki uğraşamayabilirim ama burada bunları benden iyi yapabilecek çok yetenekli arkadaşlar gördüm. 





















Bildirim





< Bu mesaj bu kişi tarafından değiştirildi atyay -- 10 Kasım 2011; 22:14:33 > |
|
|
|
|
< Bu mesaj bu kişi tarafından değiştirildi yesil1026 -- 11 Kasım 2011; 8:58:16 > |
|
|
|
|
|
|
|
|
|
< Bu mesaj bu kişi tarafından değiştirildi Guest-DC5C7D984 -- 11 Kasım 2011; 16:12:39 > |
< Bu mesaj bu kişi tarafından değiştirildi Rubisco -- 11 Kasım 2011; 20:30:45 > |
|
|
|