Yeni Kayıt
Yeni Kayıt






 Konudaki Resimler
Konudaki Resimler
|










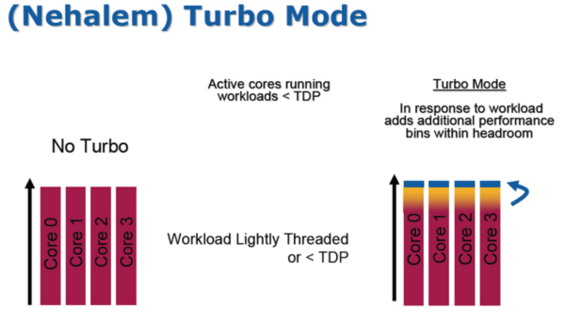


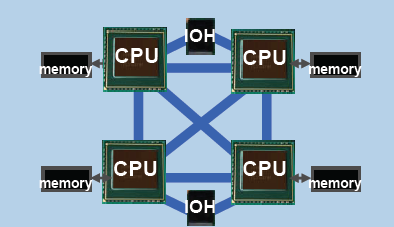

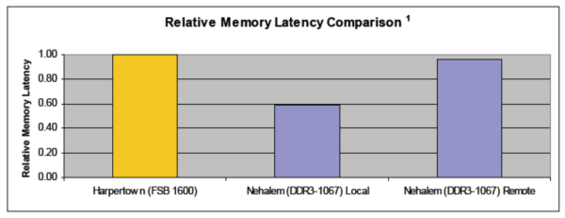
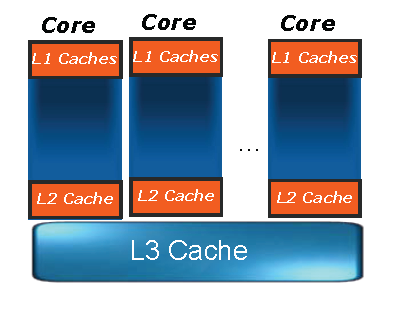

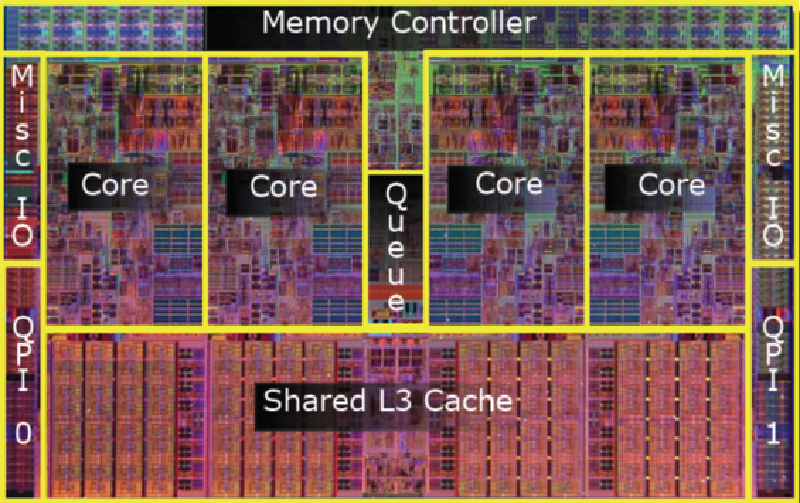


 ...türkçe terimleri anlamak zor oluyo ama anlıyorum yinede
...türkçe terimleri anlamak zor oluyo ama anlıyorum yinede :P...bi de 2 ay sonra yeni PC toplıycam Nehalem olcak büyük ihtimalle...
:P...bi de 2 ay sonra yeni PC toplıycam Nehalem olcak büyük ihtimalle...





















Bildirim



 JVC UX-C25DAB – Micro HiFi sistemi, CD, USB, Bluetooth, DAB+, UKW-RDS, Line-In ve IR uzaktan kumanda, siyah : Amazon.com.tr: Elektronik
https://www.amazon.com.tr/dp/B0B8HJL3HM
dün paylaşıldı
JVC UX-C25DAB – Micro HiFi sistemi, CD, USB, Bluetooth, DAB+, UKW-RDS, Line-In ve IR uzaktan kumanda, siyah : Amazon.com.tr: Elektronik
https://www.amazon.com.tr/dp/B0B8HJL3HM
dün paylaşıldı





|
|
|
|
|
|
|
< Bu mesaj bu kişi tarafından değiştirildi Trecc11 -- 22 Ekim 2008; 0:27:54 > |
|
|
|
|
|
< Bu mesaj bu kişi tarafından değiştirildi ibow -- 22 Ekim 2008; 20:55:04 > |
|
|